Chaînes de caractères en C : une histoire de pointeurs
Une réponse à la question "Comment concaténer deux chaînes en C ?" avec son explication technique.
Comment on apprend à coder
Avant de rentrer dans le vif du sujet, un point sur la manière dont on enseigne la programmation s’impose. Comme dans tout apprentissage, la programmation commence par des choses simples. Et ce n’est pas plus mal : ça permet de comprendre ce qui se passe sans trop se perdre dans des détails qui, bien qu’ayant un rôle important, ne sont pas nécessaires pour comprendre de quoi on parle.
Prenons l’exemple des mathématiques : on commence par la géométrie, où on voit bien de quoi on parle comme on peut faire un dessin, puis on démontre des cas généraux, avant de passer aux nombres complexes... Bref, on commence doucement avant de passer à plus compliqué.
En programmation les choses simples sont celles qui sont le plus éloignées du langage machine, c’est-à-dire l’algorithmique. En effet, un algorithme est une suite d’instructions que l’on écrit sans trop savoir comment tout cela sera géré concrètement, mais au fond cela nous importe peu, car seul le résultat nous intéresse. Un exemple d’algorithme, qui permet de savoir si un nombre est premier :
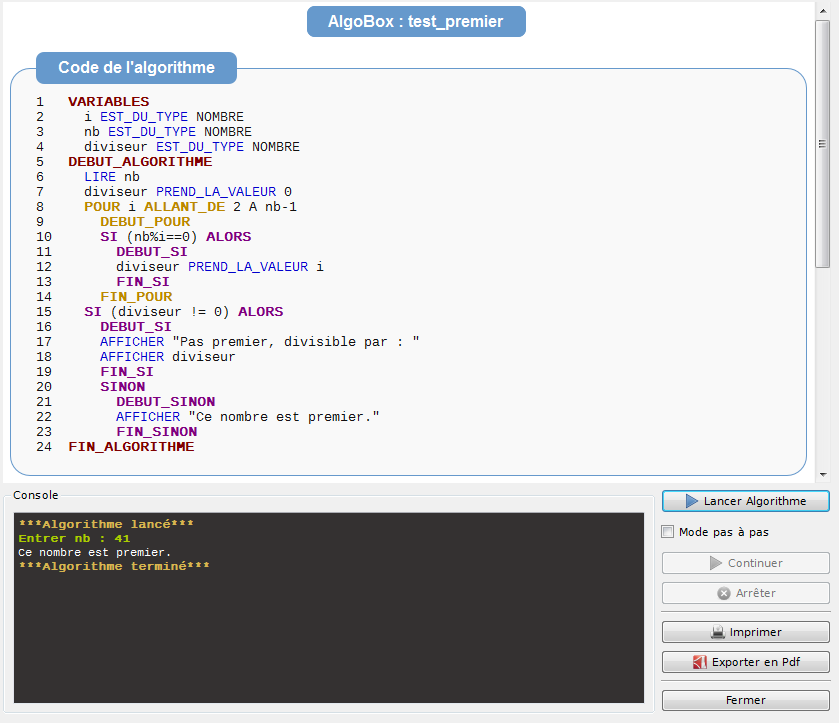
Vous pouvez vérifier, 41 est bien premier. Au passage, remarquez que nb%i retourne le reste de la division euclidienne de nb par i, donc si il vaut 0 c’est qui existe un entier k tel que nb = k*i, donc que nb n’est pas premier comme i varie entre 2 et nb-1.
Avec AlgoBox, on vient de faire de la programmation de très haut niveau car on est très loin du langage machine (cela ne veut pas dire pour autant que c’est du très haut vol !). En effet, on a écrit un algorithme; en l’exécutant on a obtenu la réponse à notre problème, et même si on n’a pas trop compris ce qui s’est passé derrière, cela nous importe peu : on a notre résultat, c’est l’essentiel.
Le problème des outils comme AlgoBox, c’est qu’ils sont rapidement limités. Quand on veut faire quelque chose d’un peu plus approfondi (par exemple une fonction qui nous retournerait vrai si le nombre est premier, et faux sinon), il faut se pencher sur des langages plus proches de la machine. On parle de langages de plus bas niveau.
De la nécessité de la technique
Et oui, le monde de l’informatique est comme tous les autres, dès que l’on veut faire quelque chose avancé, il faut se plonger dans les détails que l’on avait plus ou moins volontairement laissés de côté pour se concentrer sur l’essentiel. Reprenez l’exemple des Mathématiques, les quantificateurs sont l’exemple même de la rigueur que l’on ne s’impose pas avant le niveau lycée et qui sont pourtant indispensables si l’on ne veut pas démontrer n’importe quoi.
En informatique, ces détails sont ce que l’on appelle les langages de plus bas niveau, c’est-à-dire plus proches de la machine. Et même si vous ne vous en rendez pas compte, tout est basé là-dessus. Par exemple, pour lancer mon algorithme, AlgoBox a eu recours à un langage de plus pas niveau pour interpréter ce que j’ai écrit, et le convertir en quelque chose de compréhensible par mon ordinateur. Dans notre cas, AlgoBox est programmé en utilisant du C++, et a recours à la librairie QT (elle aussi programmée en C++) pour gérer l’interface.
Vous l’aurez compris, même si vous ne vous en servez pas directement, les langages de bas niveau sont utilisés dans tous les logiciels que vous utilisez. Et c’est d’ailleurs le cas en ce moment car le navigateur web que vous utilisez pour lire cet article a sans doute été programmé en utilisant un langage de bas niveau, probablement le C++.
Intérêt des langages de bas niveau
Les langages de bas niveau présentent l’intérêt d’être plus rapides car ils n’ont pas besoin d’un interpréteur comme c’était le cas avec mon algorithme qui a eu besoin d'AlgoBox pour être exécuté. Dans l'exemple précédent, AlgoBox a joué le rôle de l'interpréteur : il a analysé mon algorithme et l'a converti en quelque chose de compréhensible par mon ordinateur pour ensuite l'exécuter et me donner le résultat. Tous les langages de haut niveau ont besoin d’un tel outil pour pouvoir exécuter un programme. C’est le cas de PHP, Python, Javascript (dont un interpréteur connu est V8, utilisé dans Node.JS ou le navigateur Google Chrome), et bien d’autres!
De plus, les langages de bas niveau permettent de réaliser plus de choses car ils exploitent pleinement les capacités de votre ordinateur étant donné qu'ils peuvent être directement transformés en langage machine par un procédé que l’on nomme la compilation. Une fois compilé, le programme est directement interprétable par votre machine, et c’est pour cela qu’il est plus rapide.
Introduction au C
Le langage C est apparu en 1972 pour remplacer le B et est aujourd’hui, avec son extension C++, considéré comme le langage de bas niveau de référence. Une écrasante majorité des programmes ayant recours à des langages de bas niveau l’utilisent aujourd’hui, ce qui en fait un langage très populaire parmi les développeurs. Voici un exemple très basique de programme en C qui réalise l'opération 2 + 9 * 6
Pour compiler un programme en C, on a recours à un compilateur. Sous Linux, on procède comme ceci :
Un langage typé
Vous l’aurez remarqué, pour utiliser une variable il faut la déclarer en donnant son type dans le programme (c’est à cela que sert le int devant le nom de la variable). Cela n’est pas le cas dans d’autres langages de plus haut niveau comme le PHP. En PHP, pour obtenir le même résultat, on aurait fait comme ça :
Et ça marche, pas besoin de préciser le type de $a, $b, $c : PHP le détecte tout seul. Alors pourquoi a-t-on besoin de le faire en C ? Plusieurs raisons ont poussé les concepteurs de ce langage à forcer cela, notamment la performance. Prenons le cas de la division de 5 par 2, qui donne un nombre à 1 décimale : 2,5.
En exécutant le programme, on obtient 2 (!), car le C ne s’est pas préoccupé de savoir s’il y avait quelque chose après la virgule, il a simplement fait son calcul et s’est arrêté à la partie entière car il fait la division de deux entiers. Cela permet d’être sûr d’avoir toujours le même type de donnée retourné lors de la division de deux entiers : un entier.
Pour obtenir le résultat attendu, il faut indiquer au C que l’on souhaite travailler avec des nombres à virgules (de type float) au niveau des deux variables a et b, la division retourne alors un nombre à virgule, et on a bien 2,5.
Tout cela n’est pas nécessaire avec un langage de plus haut niveau. En PHP, on aurait fait comme ça :
Et on obtient bien 2,5. Pour obtenir ce résultat, PHP, qui a stocké $a et $b comme des entiers (pour pouvoir supporter des plus grandes valeurs), a regardé si 2 divisait 5, ce qui n’est pas le cas, et a donc traité la division comme division de deux nombres à virgules pour finalement obtenir 2,5. Cela oblige PHP à réaliser des opérations supplémentaires que notre programme en C ne fait pas. Par conséquent, si l’on souhaite réaliser de très nombreuses divisions, le C sera largement plus performant que PHP !
Comment j'imaginais les chaînes en C
Un caractère est, en C, de type char. En me promenant sur Internet, j'ai vu que les chaînes de caractères étaient déclarées comme ceci : char* machaine="Bonjour!";. J'en ai donc déduit que le type des chaînes de caractères étaient de type char*. Et j'ai tenté un truc étrange pour concaténer mes chaînes :
Quand j'ai voulu compiler ça, j'ai pas vraiment été bien accueilli...
Bon, il avait raison : en C, l'opérateur . est utilisé pour les structures (une petite recherche sur votre moteur de recherche préféré vous en dira plus à ce sujet, ce n'est pas vraiment intéressant ici). Donc je me suis dit que j'allais essayer de faire ça façon Javascript, c'est-à-dire avec un + :
Sans plus de succès :
J'étais un peu perdu, alors j'ai fait quelques recherches sur le sujet des chaînes de caractères et la manière dont on les traite en C. Et, comme en mathématiques, pour expliquer l'inexplicable, un retour aux définitions s'impose !
Qu'est-ce qu'une variable ?
Une question simple en apparence : une variable, c'est un nom auquel on attribue une donnée pour la réutiliser plus tard. Jusque là rien de spécial. En fait, la vraie question est de savoir comment cela est géré par votre ordinateur.
Le contenu des variables est stocké dans la mémoire vive (RAM) de votre ordinateur. Il s'agit d'un espace de stockage qui est effacé à chaque redémarrage de votre ordinateur, à la capacité largement inférieure à celle d'un disque dur, mais qui présente l'intérêt d'être très rapide, idéal donc pour stocker des petites informations comme des nombres ou des caractères. Mais une fois l'information stockée, le problème va être de savoir comment on peut la retrouver. Pour cela, votre ordinateur découpe la mémoire vive en plusieurs cases, et attribue à chacune d'elles une adresse (qui correspond à un numéro).
Cependant, votre programme n'est pas tout seul à s’exécuter sur votre système : entre votre navigateur web, le lecteur multimédia, le logiciel de messagerie instantanée, le service de mises à jour et j'en passe, la mémoire est utilisée par beaucoup de monde. Pour éviter que certains programmes n'utilisent la même case, il y a un chef d'orchestre répondant au doux nom de noyau (kernel en Anglais). Dès que vous avez recours à une variable, le noyau en prend note et retourne à votre programme une adresse correspondant à une case inutilisée dans laquelle votre programme peut stocker le contenu de la variable, pour pouvoir le réutiliser plus tard.
Dans les cas des tableaux (un ensemble de données les unes à la suite des autres), il y a une petite variante : comme il y a plusieurs valeurs, chaque tableau correspond à une zone de plusieurs cases consécutives dont le contenu correspond aux différentes valeurs du tableau.
Une histoire de pointeurs
Qu'est-ce qu'un pointeur dans tout ça ? Il s'agit tout simplement d'une adresse vers une case de la mémoire. Ainsi, lorsque vous utilisez une variable dans un programme, le noyau retourne en réalité un pointeur à votre programme (vers la case de la variable, ou vers la première valeur pour un tableau). Ce pointeur permet à votre programme de savoir où il doit stocker son contenu, pour ne déranger personne. Plus tard, lorsque vous réutilisez la variable, votre programme se souviendra de l'adresse correspondant et ira travailler avec la case mémoire en question.
En temps normal, les pointeurs sont bien cachés derrière les variables comme il faut un certain niveau de connaissances pour savoir à quoi cela correspond, mais il y a toujours moyen de les réveiller un peu, surtout avec les tableaux, étant donné qu'un tableau est fait d'un pointeur vers la première valeur du tableau. Pas convaincu ? Compilez ce code :
Le compilateur nous indique un truc bizarre avec int* : le tableau a serait de type int*. Or, c'est un tableau ! Dès lors, à quoi peut bien correspondre le caractère *, à côté de int ?
Signification de l'étoile : un pointeur !
Vous savez où on a déjà vu cette étoile ? C'était quand je vous parlais du type char* qui correspond à une chaîne de caractères. Or, qu'est-ce qu'une chaîne, si ce n'est une suite de caractères, que l'on pourrait donc assimiler à un tableau de caractères ?
Ça coïnciderait à ce que l'on vient de voir avec le tableau d'entiers... Et en fait c'est plus ou moins ça. L'étoile indique un pointeur, et un tableau correspond à un pointeur, vers la première case du tableau. Avant de démontrer cela, voyons rapidement comment utiliser les pointeurs.
Utilisation des pointeurs en C
Rien ne vaut un bon vieil exemple pour voir comment tout cela fonctionne.
En compilant tout ça, on obtient bien le résultat attendu : on a indirectement modifié le contenu de a en 6.
Un tableau EST un pointeur
Il y a quelques lignes, j'ai gratuitement affirmé qu'un tableau était en réalité un pointeur vers la première valeur du tableau. Vérifions cela...
On compile et on exécute le tout :
Je ne vous avait pas menti. C'est pas merveilleux ? Mais cela ne justifie pas le titre de ce paragraphe, car en réalité un pointeur est un tableau. En effet, on peut utiliser la syntaxe des tableaux sur un pointeur. Un exemple ?
En compilant tout ça, on remarque que c'est comme si b était a. C'est ce qu'on voulait montrer : un pointeur est un tableau. Il n'y a donc rien de particulièrement surprenant à avoir un tableau de type int*.
Et les chaînes de caractères ?
Une chaîne de caractères est, comme je l'ai expliqué plus haut, un tableau de caractères (de type char). Dès lors, quoi de plus normal que d'avoir des chaînes de caractères de type char* ? Ce n'est d'ailleurs pas non plus un hasard si l'on peut modifier une chaîne en utilisant la syntaxe d'un tableau : chaine[3]='a'; fonctionne et remplace le 4ème caractère (la numérotation d'un tableau, comme celle d'une chaîne, commence à 0) de chaine par la lettre a.
Mais les chaînes ne sont pas que des simples tableaux, elles bénéficient de quelques ajouts pour simplifier leur manipulation. Pensez par exemple à la syntaxe que j'ai utilisé plus haut pour déclarer mes chaînes :
Il s'agit ici d'un raccourci. En effet, comme vous le savez maintenant, une chaîne est avant tout un tableau de caractères. Est-ce que vous avez déjà réussi à déclarer un tableau en mettant tous ses caractères à la suite, comme je viens de le faire ? Personnellement je n'ai jamais réussi, il faut utiliser une syntaxe avec des crochets:
Mais ce n'est pas tout ! Vous avez forcément déjà utilisé, pour afficher une chaîne, l'indicateur %s dans printf(). Regardez par exemple ce code :
Qu'a fait ici l'indicateur %s ? Il vient d'afficher la chaîne en entier, c'est-à-dire : toutes les valeurs du tableau, les unes à la suite des autres. Cela peut sembler simple comme bonjour, mais essayez de faire pareil avec un tableau d'entiers, et vous vous rendrez compte que cela est bien plus long qu'un simple printf()! Mais pourquoi ces fonctionnalités-là sont-elles exclusives aux chaînes de caractères ? Au fond, ça simplifierai le débogage de pouvoir directement afficher un tableau d'entiers dans printf()!
Quelque chose en plus...
Si il est possible d'utiliser %s dans printf(), c'est qu'il y a un petit quelque chose en plus avec les chaînes de caractères, qui fait que cette fonctionnalité ne peut pas être implémentée avec un tableau classique.
Je vous sent impatient de découvrir le secret des chaînes de caractères, alors sans plus attendre, je vais vous le révéler : Les chaînes de caractères sont terminées par un caractère de code 0, qui correspond au caractère "Fin de chaîne" (NUL).
C'est tout ? Hé bien, oui. Alors cet article pourrait s'arrêter là, mais ça serait un peu brutal comme fin, alors on va voir un peu à quoi ça peut bien servir d'avoir ce caractère spécial en fin de chaîne.
Un 0 qui change tout
Commençons par vérifier si ce 0 est bien là...
Compilons tout ça...
Il y a donc bien un 0 à la fin de la chaîne. Et si on a un jour décidé de mettre un 0 à la fin des chaînes en C, c'est qu'il y a une bonne raison. Comme il s'agit d'un caractère qui ne correspond à aucune lettre, on peut être sûr qu'on ne le retrouvera pas dans la chaîne. Ce 0 permet donc d'indiquer avec certitude que la chaîne de caractères étudiée s'arrête là.
Application à printf()
Vous le savez aussi bien que moi, en informatique comme ailleurs il n'y a pas de magie. Et printf() n'échappe pas à la règle : si vous ne lui envoyez qu'un argument, la fonction ne reçoit que l'argument et rien de plus. Or, lorsque l'on veut afficher une chaîne avec printf(), l'argument correspondant est de type char*. Autrement dit, il s'agit d'un pointeur vers le premier caractère de la chaîne.
Lorsqu'elle reçoit un argument de ce type, printf() va afficher les caractères un par un, en les lisant les un à la suite des autres. Et ce jusqu'à rencontrer le caractère 0, qui lui indique la fin de la chaîne. Ce caractère est le seul moyen pour printf() de savoir où s'arrête votre chaîne. Et si vous l'enlevez, printf() va continuer à lire dans la mémoire, même en dehors de votre chaîne, et il va se passer des choses vraiment étranges. Pas convaincu ? Essayez ce code :
Sous Windows, quand on lance ce code, on obtient quelques caractères supplémentaires... Certes, c'est plutôt joli, mais ce n'est pas vraiment le résultat attendu. Et si vous n'avez pas de chance, vous aurez même un bip (qui indiquerait que printf() a lu un caractère de code 7).

Ici, printf() a continué à lire dans la mémoire jusqu'à lire un 0. Cela l'a obligé à lire 3 caractères en plus dans notre cas. Mais ça peut être beaucoup plus si il n'y a pas de 0 tout de suite! Prenez cet exemple, où l'on triche un peu comme on manipule la mémoire après...
Le comportement de ce code est le même que si on avait modifié quelques caractères de la chaîne. Et donc forcément on aura en sortie "Salut ! une chaîne.....". Maintenant, essayons avec un 0 à la fin :
Ce code affiche bien "Salut !", et c'est tout. printf() s'est donc bien arrêté au caractère de code 0, c'est ce que l'on souhaitait démontrer !
Concaténation de deux chaînes
Revenons à notre problème initial : la concaténation de deux chaînes. Maintenant que nous savons comment tout cela fonctionne, concaténer deux chaînes ne se révèle pas spécialement compliqué : il faut juste copier les caractères un par un puis penser à ajouter un caractère de code 0 à la fin de la chaîne.
En compilant ce code, et en l'exécutant, on a bien le résultat attendu : "Bonjour, TPXP". Vous l'aurez remarqué, la concaténation est ici un peu plus compliquée qu'un simple caractère. Mais au moins, on comprend exactement ce qu'il se passe, et on contrôle directement la mémoire, alors que les opérateurs en Javascript/PHP ont quelque chose de magique, puisqu'ils cachent toute cette petite logique. Au pire, si vous n'avez pas envie de tout refaire à chaque fois, vous pouvez utiliser la fonction strcat() (définie dans strings.h), qui retourne la concaténation des deux chaînes.
C'est ce qui fait toute la force du C : on est très proche de la mémoire, et on peut par conséquent la manipuler très facilement. Mais on peut aussi se cantonner à des fonctions prédéfinies qui font aussi très bien le travail !
Aller plus loin : la puissance des pointeurs
Voilà pour la solution au problème de la concaténation des chaînes. Maintenant que l'on a une réponse fonctionnelle, voyons en quoi les pointeurs peuvent se révéler très utiles dans certains cas...
Erreur de Segmentation
Mais avant de nous pencher sur ce que peuvent nous apporter les pointeurs, voyons comment les choses peuvent se passer si un pointeur est bogué. Pour ce faire, on va définir un pointeur par son adresse directement, et pour faire les choses bien, on va le faire pointer à l'adresse 0 (NULL).
On dirait que ça ne s'est pas aussi bien passé que prévu... En effet, le pointeur a pointe ici vers l'adresse 0, qui n'est vraisemblablement pas attribuée à notre programme. Le noyau, qui est responsable de la gestion de la mémoire, remarque cela et, sans autre forme de procès, arrête immédiatement le programme. Il ne faudrait tout de même pas pas qu'il continue à mettre le bazar ailleurs, quand même ! Ici, le programme tente d'accéder à une zone de la mémoire qui n'est pas la sienne, et cela déclenche une erreur de segmentation. Le plus souvent, celle-ci est causée par une erreur dans la conception du programme (par exemple, un cas non envisagé). Ici, on en a volontairement généré une, mais parfois cela peut être un peu plus tordu.
C'est le cas lorsque l'on utilise des données statiques, par exemple une chaîne de caractères programmée en dur, et que l'on souhaite les modifier.
Ce code produira une erreur erreur de segmentation, car la chaîne a est considérée comme invariante. Son pointeur est donc un petit peu particulier car il ne correspond à rien dans la mémoire, d'où l'erreur de segmentation comme la case pointée n'existe pas. Par contre, si on définit notre chaîne comme un tableau, on aura pas ce problème. En effet, le compilateur considèrera alors la chaîne comme un tableau, et stockera toutes ses cases dans la mémoire, on pourra donc les modifier. Cette histoire de tableau peut sembler un peu farfelue, mais c'est comme ça que votre code est interprété, alors autant le savoir...
Les erreurs de segmentation sont partout. Vous avez forcement déjà vu ce message sous Windows :
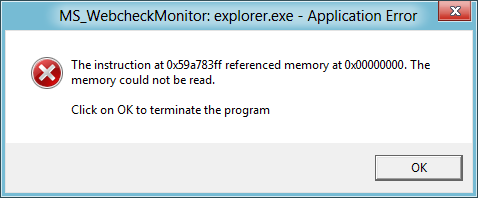
Il s'agit de la manière de Windows de signaler une erreur de Segmentation. Ici, le programme a tenté d'accéder à l'adresse 0x000000, c'est-à-dire l'adresse NULL, ce qui provoque, comme nous l'avons vu plus haut, une erreur de segmentation. Notez que si vous essayez le code précédent qui génère une erreur de segmentation en tentant d'accéder à l'adresse NULL, vous aurez peut-être le message "<truc.exe> a cessé de fonctionné à la place de la boîte de dialogue ci-dessus. A priori, la différence entre ces messages pourrait être le compilateur utilisé (par exemple, Code::Blocks utilise GCC et VisualStudio utilise un compilateur maison), ou l'utilisation d'une librairie. Si vous avez des informations à ce sujet, vous pouvez gagner des points sur SuperUser (et devenir un héros) en répondant à cette question.
Tableaux et fonctions
Tableau en argument
Si un jour vous avez essayé d'utiliser un tableau dans une fonction, le résultat a pu vous paraître étrange. En effet, lorsque vous passez à une fonction un tableau, celle-ci peut le modifier directement. Cela peut amener à des résultats inattendus, les variables des fonctions étant avant tout locales.
Mais c'est quoi déjà un tableau, à part un pointeur ? Vous voyez où je veux en venir : vous avez passé à votre fonction un pointeur. Résultat : seule l'adresse était modifiable indépendamment. Mais à partir du moment où vous avez modifié le tableau, vous travailliez sur la même mémoire que l'autre partie du programme, et donc vos modifications étaient répercutées partout ailleurs. Peut-on parler de bug ? Pas vraiment ! En fait, c'est plutôt une fonctionnalité, qui peut se révéler utile pour traiter les données d'un tableau. Un exemple, avec cette fonction qui range les valeurs du tableau des l'ordre croissant :
Comme vous pouvez le voir, on vient de ranger notre tableau dans l'ordre croissant, sans avoir besoin d'utiliser un autre tableau. Pas mal, non? Comme on dit : It's not a bug, it's a feature : Ce n'est pas un bogue, c'est une fonctionnalité!
Retourner un tableau
Et si on veut quand même retourner un tableau ? Ça peut servir pour retourner deux variables au lieu d'une, et faire une structure juste pour ça c'est quand même lourd, en particulier pour un tableau de longueur variable, par exemple une chaîne!
Si vous essayez de retourner un tableau que vous définissez vous-même dans votre fonction, ça risque de mal se passer car le tableau sera considéré comme une variable locale, détruite à la fin de l'exécution de votre fonction. Vous retournerez donc un pointeur, mais vers une zone de mémoire effacée, et dans la grande majorité des cas ça ne marchera pas comme prévu. En tout cas, vous aurez un avertissement du compilateur, et ça fait mauvaise impression !
Pour éviter ce problème, il suffit de définir l'espace mémoire pris par votre tableau comme partagé avec tout le programme. Pour ce faire, il existe une petite fonction dénommée malloc() (définie dans stdlib.h), qui se charge de demander une zone de mémoire d'une certaine taille, et vous retourne le pointeur vers celle-ci. Plus qu'à la remplir, et vous pouvez retourner votre pointeur tranquille! Un exemple, pour faire une division euclidienne et retourner le reste et le quotient :
Arguments modifiables
Une autre utilité des pointeurs est de permettre d'avoir des arguments modifiables. Inutile? Pas si sûr! Certaines fonctions système y ont parfois recours. Cela permet par exemple de retourner un code d'état, mais de marquer un argument comme modifié pour que les fonctions appelées plus tard adaptent leur comportement en fonction du paramètre en question.
Prenons l'exemple des sockets, utilisés pour communiquer avec le réseau, par exemple pour un serveur web type Apache ou nginx. La fonction accept() prend en deuxième paramètre un pointeur vers une structure sockaddr, qu'elle remplit, et on peut à l'aide de ce paramètre connaître l'adresse IP de l'émetteur de la requête reçue. La fonction retourne quant à elle un ID de socket, ou un code d'erreur. Cela évite à la fonction d'allouer à chaque nouvelle requête de la mémoire, alors qu'elle peut grâce à ce pointeur réutiliser la mémoire allouée pour les requêtes précédentes. De plus, on a directement en valeur retournée quelque chose d'exploitable dans la suite, pas besoin d'utiliser une structure ou un tableau, ce qui rend le code un peu plus simple. En effet, on peut directement envoyer la valeur de retour dans une condition, et s'arrêter si on a une erreur; si l'on avait une structure, la syntaxe serait un peu plus compliquée, ce qui rendrait le code moins lisible.
Conclusion
Vous l'aurez compris, les pointeurs sont extrêmement utiles, et ils sont utilisés un peu partout. C'est une fonctionnalité extrêmement puissante que l'on ne retrouve pas dans les langages de plus haut niveau, on peut donc parler d'une fonctionnalité qui fait la force et le charme du C et plus généralement des langages de bas niveau. J'espère que cet article vous a permis d'y voir plus clair à ce sujet, et que la prochaine fois que vous verrez une étoile dans un code en C cela ne vous posera pas de problème.
Bon code!