Décodage de l'encodage vidéo
Une plongée dans le monde merveilleux des sigles qui font peur comme h264, x264, mpeg, avi, mp4, et d'autres !
Les systèmes d'information actuels permettent de transmettre des données, sous forme binaire (des mots très longs constitués de 0 et 1). C'est plutôt pratique, mais avant de transmettre des données il faudrait en avoir ! Or, le processus pour passer d'une vidéo à un mot binaire ne semble pas évident... Vous avez peut-être déjà entendu parler de codecs, h264, mkv, avi ou d'autres sigles qui vous ont semblés obscurs. Face à ça, le bon réflexe que vous avez sûrement adopté est d'utiliser VLC... D'accord, mais pourquoi ça marche, qu'est-ce qui empêche le lecteur multimédia installé auparavant sur votre PC de lire ce fichier ? Aujourd'hui, nous allons essayer d'éclaircir tout ça !
Qu'est-ce que la vidéo ?
Avant de nous demander comment transformer la vidéo en mot binaire (on parle d'encodage), il convient de se rappeler avec quoi on travaille, ce qui permettra d'encoder de manière plus efficace le contenu.
On peut distinguer dans une vidéo deux parties : le son, et l'image. On peut éventuellement ajouter d'autres choses, par exemple des sous-titres, plusieurs langues audio, des métadonnées (informations supplémentaires sur le contenu, par exemple le nom du film), mais pour l'instant on va s'en tenir au son et à l'image, ça sera déjà pas mal. 😄
Acquisition du son
Pour convertir le son en mot binaire (on parle de numérisation), on commence par utiliser un microphone. Ce microphone convertit les vibrations accoustiques en signal électrique, puis on mesure l'amplitude de ce signal électrique, ce qui nous donne un nombre que l'on convertit en binaire. Comment me direz-vous ?
Petit rappel sur les nombres binaires
Un nombre binaire est un ensemble ordonné de 0 et de 1 (chaque valeur est nommée bit, pour binary digit). Chaque bit représente une puissance de deux, et les puissances de 2 les plus faibles sont -comme les nombres que nous avons l'habitude de manipuler- à droite. Pour la petite histoire, les nombres que nous avons l'habitude d'utiliser utilisent le système décimal, et utilisent les puissances de 10... Si, si, regardez !
Précision de la numérisation
La question qu'on peut alors se poser est "Combien de bits seront utilisés ?". En fait, c'est au choix ! Vous pouvez choisir autant de bits que vous voulez pour le nombre binaire correspondant, il faudra alors faire une mise à l'échelle pour que les deux plages de valeur correspondent.
Par exemple, si le microphone donne des valeurs allant de -5V à +5V, et que l'on veut utiliser 3 bits pour la numérisation, il faut que le nombre binaire 000 corresponde à -5V, et que 111 corresponde à +5V. Si prend un écart constant entre les valeurs, sachant que l'on a 2³ valeurs possibles, on obtient : (5 - (-5))/(2³ - 1) = 1,43 Volt/unité.
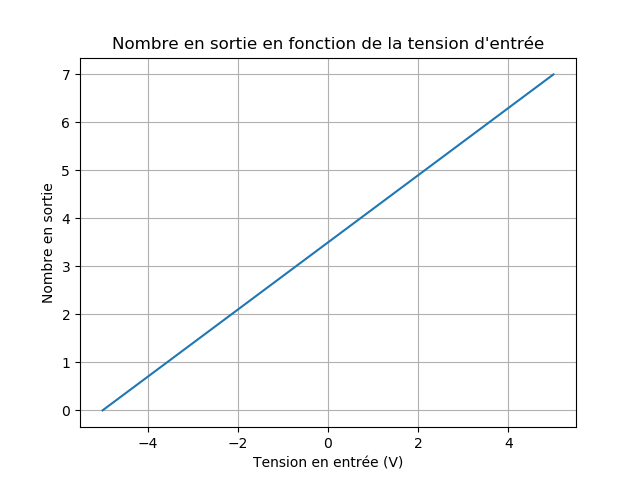
... Enfin, presque ! Parce que avec cette méthode, on peut avoir en sortie des nombres à virgule ! Par exemple, à 0V, il faudrait stocker 3,5 ! On crée plutôt 8 intervalles consécutifs, auxquels on associe une valeur binaire : on parle de discrétisation. Comme ceci :
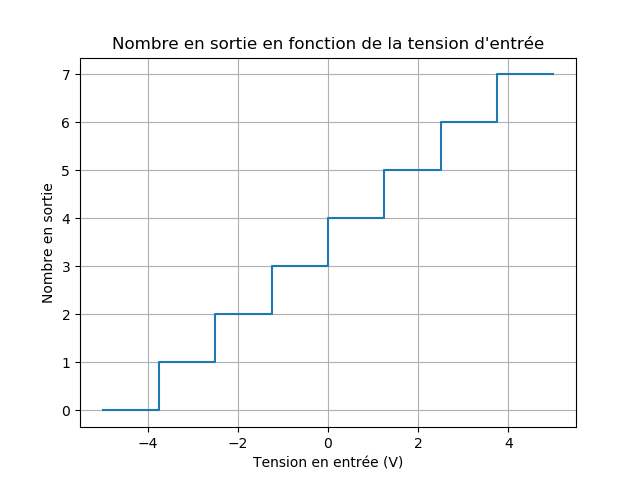
On a une forme d'escalier car à un nombre binaire peuvent correspondre plusieurs tensions d'entrée ! La discrétisation introduit une erreur, que l'on peut réduire en augmentant le nombre de bits utilisés. Par exemple, pour 8 bits : (5 - (-5))/(2⁸ - 1) = 0,04 Volt/unité, on a quelque chose de nettement plus fidèle :
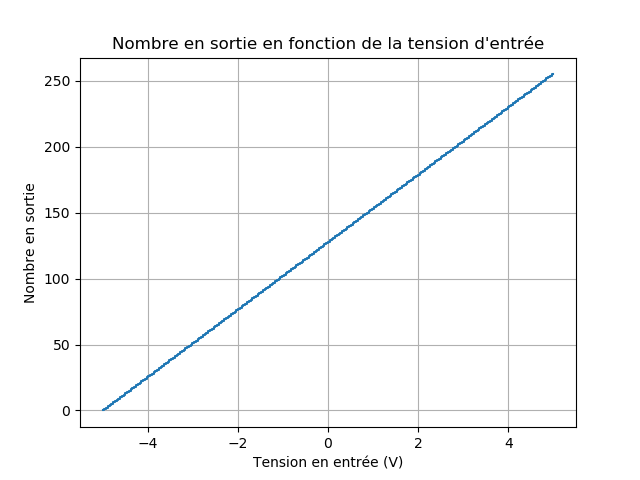
En pratique, on prend généralement 16 bits pour chaque valeur, mais il arrive que l'on choisisse 24 bits pour les enregistrements en studio par exemple.
Échantillonnage
Maintenant que l'on sait comment on va enregistrer notre valeur, il faut savoir quand on va la relever ! En effet, on ne peut pas enregistrer en continu la valeur d'entrée, sans quoi il y aurait une infinité de valeurs !
On a donc choisi d'enregistrer les valeurs (on parle d'échantillons) à intervalles réguliers. Cet intervalle est nommé période d'échantillonage et -comme toute période- on peut lui associer une fréquence, dite fréquence d'échantillonnage qui est l'inverse de la période d'échantillonnage.
Le relevé de chaque échantillon est nommé échantillonnage (en Anglais, sampling) et, afin de garantir une restitution fidèle du son, il convient d'avoir une fréquence d'échantillonnage assez élevée ! D'après le théorème de Shannon, il faut que la fréquence d'échantillonnage soit au moins 2 fois supérieure à la fréquence maximale du signal en entrée.
Sachant que l'on travaille avec les fréquences audibles par l'être humain (de 20Hz à 20 kHz), on doit donc avoir une fréquence d'échantillonnage supérieure à 40 kHz. En pratique, on a l'habitude de prendre 44,1 kHz pour avoir un peu de marge.
Anecdote : Choix de la capacité du CD
Pour la petite histoire, la capacité de 700 Mo d'un CD n'a pas été choisie au hasard ! Si l'on prend la capacité d'un CD, que l'on la convertit en bits, sachant qu'un octet est composé de 8 bits, et que les puissances de 10 en informatique sont un peu particulières : on prend 10³ = 2¹⁰ = 1024, on obtient 700 × 1024 × 1024 × 8 bits...
... Que l'on divise par la taille d'un échantillon pour savoir combien d'échantillons de 16 bits on peut stocker : (700 × 1024² × 8) / 16 = 350 × 1024² ...
... Que l'on divise ce nombre par la durée correspondante, sachant que l'on échantillonne à 44,1 kHz : (350 × 1024²)/44100 = 8322 s...
... Et que l'on divise par les deux canaux audio (gauche et droite), on obtient : 8322/2 = 4161 s = 1 h 9 min, ce qui correspond à peu près à la durée d'un album ! C'est exactement pour cette utilisation que l'on a dimensionné le CD. Souvenez-vous, le CD était à l'époque un remplaçant du vinyle, et il se devait d'être au moins aussi performant, on a donc mis au point ce support pour qu'il permette de stocker de manière brute environ une heure de musique.
Conclusion
La numérisation d'un signal audio consiste à transformer ce signal en un ensemble ordonné de 0 et de 1 qui le représentent. Pour cela, on a recours à deux procédés : l'échantillonage, qui transforme le signal en un nombre fini de valeurs, et la numérisation, qui convertit ces valeurs en nombres binaires. La suite de ces nombres binaires donne une réprésentation binaire du signal.
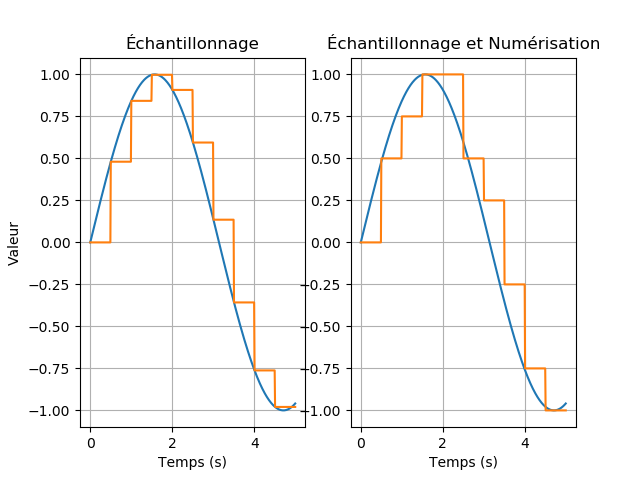
Une petite remarque : ce n'est pas parce que le signal numérisé a un léger retard que c'est un problème ! A la lecture, il n'est pas gênant que le son ait un léger retard. Quand bien même ce serait le cas, ce retard est si faible (1/44100, moins d'un millième de seconde !) qu'il n'est pas perceptible.
Acquisition de la vidéo
Pour ce qui est de la vidéo, il faut acquérir une image. On commence par diviser l'image en petits carrés nommés pixels puis on place un capteur lumineux pour chaque pixel. Ces capteurs lumineux réalisent la décomposition de la lumière incidente en ses 3 composantes principales : rouge, vert et bleu et retournent les 3 valeurs sous forme binaire, généralement sur 8 bits. Cela fait tout de même 256³=16 millions de couleurs !
Comme vous vous en doutez, un pixel est très petit ! C'est le composant de base d'un écran, et on le divise en 3 parties (Rouge, Vert et Bleu) pour pouvoir afficher une des 16 millions de couleurs possibles. On arrive à les distinguer en utilisant une loupe puissante (merci à Dinesh Dhankhar pour la photo) :
{kind=link}
![]()
Et voici à quoi ressemble un capteur d'un appareil photo, ici celui du Samsung Galaxy S (merci à Petar Milošević pour la photo) :
{kind=link}

Lorsque l'on demande à ce capteur de prendre une photo, il retourne pour chaque pixel du capteur les composantes rouges vertes et bleues de la lumière captée par la cellule du capteur correspondant au pixel.
Pour une image en 1080p (1920 × 1080 pixels), cela représente : 1920 × 1080 pixels, or chaque pixel est representé sur 3 × 8 = 24 bits, ce qui nous fait un total de 1920 × 1080 × 24 = 47,5 Mbits = 5,9 Mo. Ça commence à faire beaucoup, en particulier puisqu'il ne s'agit que d'une seule image !
Pour que l'on ait l'impression de mouvement (et pas l'impression de diaporama), il faut que l'on affiche au moins 24 images par seconde. Pour une vidéo d'une heure (sans son), cela correspond à : 3600 × 24 × 5,9 × 1024² = 500 Go, largement au dessus des capacités des supports de stockage actuels (pour rappel, les disques BluRay ont une capacité de 128 Go au maximum).
Plus que stocker les données, il faut donc en trouver une représentation efficace, afin de garder la taille des fichiers raisonnable. Imaginez un peu si vous deviez changer de disque en plein milieu de votre film préféré ! C'est pour éviter cela que l'on eu l'idée de l'encodage vidéo : compresser les données vidéo, audio ou image afin de réduire leur taille et rendre le transfert de ces données possible !
Encodage (ou compression) vidéo
Maintenant que nous sommes convaincus de l'intérêt de l'encodage vidéo, voyons comment tout cela est mis en place.
Les encodages vidéo sont développés par le Moving Picture Experts Group. Leur rôle est de trouver des manières d'enregistrer des vidéos dans un format plus léger, afin de répondre aux besoins mondiaux (rien que ça !). Ainsi, les derniers encodages du MPEG s'inscrivent dans le contexte actuel de démocratisation des contenus en Haute Résolution, ils sont donc étudiés pour l'encodage des vidéos à des résolutions plus élevées.
Principe de l'encodage vidéo
Dans la pratique, un l'encodage d'une vidéo consiste en un grand nombre d'opérations mathématiques... Pas très digeste, tout ça. Nous allons donc nous en tenir à l'idée de l'encodage, et ce qui le rend efficace dans la réduction de la taille des fichiers vidéo.
Généralement, dans un film ou une vidéo, les images se ressemblent beaucoup, surtout quand il s'agit de deux images qui se suivent. L'idée de l'encodage est donc d'étudier la ressemblance entre les images précédant l'image à encoder et d'enregistrer uniquement les différences. Ainsi, lors d'un changement de scène, on aura plus de données à stocker, mais si la vidéo est -par exemple- un paysage, on pourra s'appuyer sur la ou les image(s) précédente(s) pour reconstituer l'image ! Les meilleurs encodages sont même capables de détecter du mouvement, un changement d'orientation... Et grâce à tout ça on arrive à réduire la taille d'un film à une dizaine de Gigaoctets, soit une compression avec un facteur d'au moins 50 !
Comme vous pouvez vous en douter, la compression d'une vidéo requiert sa décompression lors de la lecture. Cette décompression consiste également à réaliser des calculs mathématiques pour déterminer chaque image, éventuellement en s'appuyant sur les images précédents. Ce sont des calculs assez intensifs, et il faut qu'ils soient faits rapidement puisqu'il y a au moins 24 images à décoder par seconde ! Les systèmes les moins puissants ont donc recours à des circuits matériels optimisés pour ce genre d'opérations... C'est un facteur important auquel font attention les membres du MPEG : si l'on crée un encodage surpuissant qui est capable de compresser une vidéo avec un facteur très important, mais que le décodage est trop complexe pour les systèmes actuels, cet encodage ne sera pas utilisé !
Encodages utilisés
Avec l'augmentation des capacités de calcul des machines, les derniers encodages ont des fonctionnalités supplémentaires qui leurs permettent de compresser de manière plus efficace la vidéo. En regardant l'historique des codecs, on voit bien cette tendance à compliquer les encodages.
A l'heure actuelle, le format d'encodage le plus utilisé est MPEG-4. La première version est sortie en 1999, puis le MPEG a ajouté quelques fonctionnalités supplémentaires pour créer AVC (Advanced Video Codec), aussi connu sous le nom de H.264. H.264 est utilisé pour la plupart des flux vidéo aujourd'hui : streaming vidéo, TV en HD, certains films sur BluRay,... Et pour s'adapter à tous ces usages, H.264 a des variantes, nommés profils, qui supportent plus ou moins de fonctionnalités, selon ce qui est possible/faisable pour une application donnée. Par exemple, certains profils proposent un précision de 8 bits par composante de couleur pour chaque pixel (Rouge, Vert, Bleu), alors que d'autres permettent d'aller jusqu'à 10 bits pour une avoir un meilleur rendu des couleurs. Si ça vous intéresse, vous pouvez jeter un oeil à la liste des profils sur Wikipédia, ou consulter les documents de référence du MPEG.
Les contenus en résolution plus faible (TV sur ADSL, DVD,...) ont quant à eux recours à un encodage un peu moins puissant, ancêtre du MPEG-4 : le MPEG-2. Il a moins de fonctionnalités, ce qui le rend moins efficace, mais est moins exigeant pour le décodeur et l'encodeur, ce qui en fait l'encodage de choix pour les appareils plus anciens.
En 2013, un nouvel encodage est sorti. Il a pour nom HEVC (High Efficiency Video Coding), ou H.265. Il s'agit d'une nouvelle extension de MPEG-4 permettant de réduire encore plus la taille des fichiers vidéo, mais aussi plus exigeante en terme de performances... Petit à petit les appareils supportant cet encodage apparaissent sur le marché, mais l'écrasante majorité des appareils en circulation n'étant pas capable de le décoder de manière acceptable, il est encore loin de devenir le standard partout.
Implémentations des encodages : codecs
Une fois l'encodage standardisé par le MPEG, il faut implémenter tout ça ! On nomme codec un programme ou une puce capable de convertir (encoder) un flux vidéo dans un encodage et l'opération inverse (décodage). C'est d'ailleurs de là que vient le nom de codec : coding/decoding. La plupart des ordiphones (smartphones si vous préférez...) sont équipés d'un codec H.264, parfois intégré dans leur processeur.
L'un des encodeurs H.264 les plus utilisés est x264, développé par VideoLAN. Il en existe de nombreux autres, capables par exemple de profiter des capacités de la carte graphique pour encoder plus rapidement. x264 est préféré aux autres pour sa meilleure efficacité et son support d'un plus grand nombre de fonctionnalités.
Toutefois, appeler un codec ne peut se faire comme ça, cela nécessiterait d'avoir toutes les images décodées, ce n'est pas souhaitable au moins pour l'espace que ça prend ! Les codecs sont donc intégrés dans un logiciel qui centralise le décodage et l'encodage pour réaliser une conversion de flux vidéo. On peut citer l'excellent FFmpeg, qui est très complet quoique un peu difficile à prendre en main !
Mettons tout cela ensemble : conteneurs !
Une fois les flux audio et vidéo mis ensemble, il faut mettre tout cela ensemble dans un seul fichier. Ce fichier respecte le format d'un conteneur multimédia, et a pour objectif de stocker la vidéo, l'audio et les métadonnées de manière efficace pour en faciliter la lecture.
Il existe de nombreux formats de conteneurs multimédia, et ce sont eux qui donnent l'extension au fichier vidéo. Vous avez peut-être connu les fichiers FLV, correspondant à des vidéos Flash ? Il s'agissait d'un format de conteneur optimisé pour les plateformes de vidéo à la demande comme Youtube, et développé par Adobe pour être utilisé avec Adobe Flash. C'était le standard de facto pour toutes les plateformes de vidéo à la demande, impossible de s'en passer à l'époque ! Il nécessitait le programme Adobe Flash Player pour être lu, et ne supportait qu'un nombre limité d'encodages, ce qui rendait sa lecture doublement difficile : le lecteur devait d'une part supporter le conteneur, mais aussi avoir un codec pour lire le flux vidéo.
Avec l'avènement de HTML5, Flash est une technologie qui a quasiment disparu, on utilise désormais H.264 sur les plateformes de vidéo à la demande. Le format de conteneur le plus utilisé sur le web pour le streaming vidéo est désormais WebM, un format de conteneur libre de droits développé par Google.
WebM s'appuie sur un format de conteneur bien connu : Matroska ! Derrière ce nom peu flatter se cache l'un des conteneurs vidéo les plus complets et le plus utilisé. Il a été étudié pour stocker la vidéo, plusieurs pistes audio, mais aussi les sous-titres, des étiquettes de catégorie, et n'importe quel fichier en pièce-jointe, par exemple une vignette ! Matroska dispose même d'un index des positions de chaque segment de la vidéo, ce qui rend le déplacement dans le fichier plus rapide. Sans cela, le lecteur multimédia doit lire tout le fichier depuis le début pour trouver le segment vidéo correspondant à un instant donné, ce qui est assez désagréable pour l'utilisateur, surtout s'il s'agît d'une vidéo en haute résolution (ce qui rend le fichier plus lourd). Une autre idée de Matroska est de stocker la portion d'audio correspondant à une portion de vidéo au même endroit. Comme ça, plus besoin de consulter deux emplacements différents du disque dur pour lire la vidéo !
Avant Matroska, on utilisait AVI (Audio Video Interleave), développé par Microsoft, ou MP4 (défini par la spécifiation de MPEG-4), mais ces formats étaient limités, que ça soit en encodages supportés, en inclusion des sous-titres ou d'autres critères comme le déplacement rapide dans un fichier... Vous pouvez trouver une comparaison des différents conteneurs vidéo sur Wikipédia.
Conclusion
Comme nous venons de le voir, l'extension d'un fichier vidéo n'indique en rien de son contenu, c'est pourquoi vous pouvez arriver à lire un fichier d'une extension donnée tout en n'arrivant pas à lire un fichier avec la même extension. L'encodage vidéo c'est tout un monde, et j'espère que cet article vous a permis d'y voir plus clair.
Bon film !